RAG + LLM: A Superpower Combination→
How Retrieval Augmented Generation turns an LLM from a storyteller into a grounded fact-checker.
How does an LLM actually understand what you type? And does ChatGPT really draw your images itself?
A model is a software program trained on a large amount of data to perform tasks, make predictions, or generate content. The creation and training of this program happen using a technology called "Deep Learning", which is a part of Artificial Intelligence.
An LLM is a model that learns patterns and relationships in human language by analyzing vast amounts of text during training. The size of this data can range between hundreds of gigabytes to even tens of terabytes. Based on what it learns during training, it can perform a variety of tasks like:
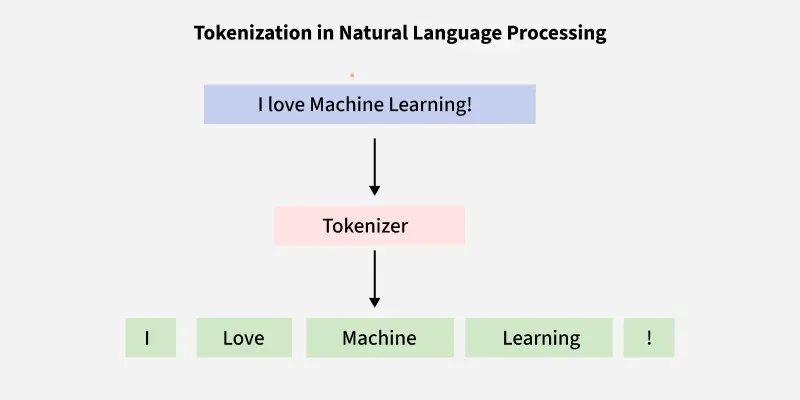
An LLM (GPT-5 by OpenAI, for example) cannot directly understand the sentence you type. Instead, It breaks down the sentence into smaller pieces called as "Tokens". This process is called as "Tokenization". These tokens are converted into numbers. This numerical data is represented in the form of "Vectors", and are stored in a database that support storing vector data. This numerical representation of text in vector form is called an "Embedding". LLM ultimately processes data as numbers.
When you ask ChatGPT to generate an image, it does not "draw" it directly, instead it sends your request to a specialized image generation model like DALL-E. It is a "Diffusion Model". These are a type of AI that creates data like images, audio or video.
Fun fact: Diffusion models create images by starting with pure noise and slowly removing it.
Let me know your thoughts, questions, or suggestions. I'm eager to learn and happy to help!